![]() The wiki is deprecated and due to be decommissioned by the end of September 2022.
The wiki is deprecated and due to be decommissioned by the end of September 2022.
The content is being migrated to other supports, new updates will be ignored and lost.
If needed you can get in touch with EGI SDIS team using operations @ egi.eu.
Difference between revisions of "MAN05 top-BDII and site-BDII High Availability"
Jump to navigation
Jump to search
| Line 3: | Line 3: | ||
[[Category:Operations Manuals]] | [[Category:Operations Manuals]] | ||
__TOC__ | __TOC__ | ||
= (EMI.gLite) top-BDII High Availability = | = (EMI.gLite) top-BDII and site-BDII High Availability = | ||
{| border="1" | {| border="1" | ||
|- | |- | ||
| '''Title''' | | '''Title''' | ||
| ''(EMI.gLite) top-BDII High Availability'' | | ''(EMI.gLite) top-BDII and site-BDII High Availability'' | ||
|- | |- | ||
| '''Document link''' | | '''Document link''' | ||
| Line 32: | Line 32: | ||
|- | |- | ||
| '''Procedure Statement''' | | '''Procedure Statement''' | ||
| ''This manual provides information on how to deploy the | | ''This manual provides information on how to deploy the BDII service in High Availability configuration. It is equally applicable to site and top BDII'' | ||
|- | |- | ||
|} | |} | ||
This document objective is to provide guidelines to improve the availability of the information system, addressing three main areas: | This document objective is to provide guidelines to improve the availability of the information system, addressing three main areas: | ||
# Requirements to deploy a TopBDII service | # Requirements to deploy a TopBDII (siteBDII) service | ||
# High Availability from a client perspective | # High Availability from a client perspective | ||
# Configuration of a High Availability TopBDII service | # Configuration of a High Availability TopBDII (siteBDII) service | ||
<br /> | <br /> | ||
= Requirements to deploy a TopBDII service = | = Requirements to deploy a TopBDII (siteBDII) service = | ||
== Hardware == | == Hardware == | ||
* dual core CPU | * dual core CPU | ||
| Line 50: | Line 50: | ||
== Co-hosting == | == Co-hosting == | ||
* Due to the critical nature of the information system with respect to the operation of the grid, the TopBDII should be installed as a stand-alone service to ensure that problems with other services do not affect the BDII. In no circumstances should the BDII be co-hosted with a service which has the potential to generate a high load. | * Due to the critical nature of the information system with respect to the operation of the grid, the TopBDII (siteBDII) should be installed as a stand-alone service to ensure that problems with other services do not affect the BDII. In no circumstances should the BDII be co-hosted with a service which has the potential to generate a high load. | ||
== Physical vs Virtual Machines == | == Physical vs Virtual Machines == | ||
* There is no clear vision on this topic. Some managers complain that there are performance issues related to deploying a TopBDII service under a virtual machine. Others argue that such performance issues are related to the configuration of the service itself. The only agreed feature is that the management and disaster recovery of any service deployed under a virtual machine is more flexible and easier. This could be an important point to take into account considering the critical importance of the TopBDII service. | * There is no clear vision on this topic. Some managers complain that there are performance issues related to deploying a TopBDII (siteBDII) service under a virtual machine. Others argue that such performance issues are related to the configuration of the service itself. The only agreed feature is that the management and disaster recovery of any service deployed under a virtual machine is more flexible and easier. This could be an important point to take into account considering the critical importance of the TopBDII (siteBDII) service. | ||
= Best practices from a client perspective = | = Best practices from a client perspective for top-BDII = | ||
* In gLite 3.2 you can set up redundancy of TopBDIIs for the clients ( | * In gLite 3.2 and EMI you can set up redundancy of TopBDIIs for the clients (WNs and UIs) setting up a list of TopBDII instances to support the automatic failover in the GFAL clients. If the first Top level BDII fails to be contacted, the second will be used in its place, and so on. This mechanism is implemented defining the '''BDII_LIST''' YAIM variable according to the following syntax: | ||
BDII_LIST=topbdii.domain.one:2170[,topbdii.domain.two:2170[...]]. | BDII_LIST=topbdii.domain.one:2170[,topbdii.domain.two:2170[...]]. | ||
| Line 69: | Line 69: | ||
<br /> | <br /> | ||
= Best practices for a TopBDII High Availability service = | = Best practices for a TopBDII (siteBDII) High Availability service = | ||
* The best practice proposal to provide a high availability TopBDII service is based on two mechanisms working as main building blocks: | * The best practice proposal to provide a high availability TopBDII (siteBDII) service is based on two mechanisms working as main building blocks: | ||
# <big>'''DNS round robin load balacing'''</big> | # <big>'''DNS round robin load balacing'''</big> | ||
# <big>'''A fault tolerance DNS Updater'''</big> | # <big>'''A fault tolerance DNS Updater'''</big> | ||
| Line 79: | Line 79: | ||
* [http://en.wikipedia.org/wiki/Load_distribution Load balancing] is a technique to distribute workload evenly across two or more resources. A load balancing method, which does not necessarily require a dedicated software or hardware node, is called [http://en.wikipedia.org/wiki/Round-robin_DNS round robin DNS]. | * [http://en.wikipedia.org/wiki/Load_distribution Load balancing] is a technique to distribute workload evenly across two or more resources. A load balancing method, which does not necessarily require a dedicated software or hardware node, is called [http://en.wikipedia.org/wiki/Round-robin_DNS round robin DNS]. | ||
* We can assume that all transactions (queries to top-bdii) generate the same resource load. For an effective load balancing, all top-bdii instances should have the same hardware configurations. In other case, a load balancing arbiter is needed. | * We can assume that all transactions (queries to top-bdii (siteBDII)) generate the same resource load. For an effective load balancing, all top-bdii (siteBDII) instances should have the same hardware configurations. In other case, a load balancing arbiter is needed. | ||
* Simple round robin DNS load balancing is easy to deploy. Assuming that there is a primary DNS server (dns.top.domain) where the DNS load balancing will be implemented, one simply has to add multiple A records mapping the same hostname to multiple IP addresses under the core.top.domain [http://en.wikipedia.org/wiki/DNS_zone DNS zone] | * Simple round robin DNS load balancing is easy to deploy. Assuming that there is a primary DNS server (dns.top.domain) where the DNS load balancing will be implemented, one simply has to add multiple A records mapping the same hostname to multiple IP addresses under the core.top.domain [http://en.wikipedia.org/wiki/DNS_zone DNS zone]. It is equally applicable to site BDII. | ||
# In dns.top.domain: Add multiple A records mapping the same hostname to multiple IP addresses | # In dns.top.domain: Add multiple A records mapping the same hostname to multiple IP addresses | ||
| Line 91: | Line 91: | ||
* The 3 records are always served as answer but the order of the records will rotate in each DNS query | * The 3 records are always served as answer but the order of the records will rotate in each DNS query | ||
* '''This does NOT provide fault tolerance against problems in the TopBDIIs themselves''' | * '''This does NOT provide fault tolerance against problems in the TopBDIIs (siteBDIIs) themselves''' | ||
# if one TopBDII fails its DNS “A” record will still be served | # if one TopBDII (siteBDII) fails its DNS “A” record will still be served | ||
# one in each three DNS queries will provide the failed TopBDII first answer | # one in each three DNS queries will provide the failed TopBDII (siteBDII) first answer | ||
== Fault tolerance DNS Updater == | == Fault tolerance DNS Updater == | ||
* The DNS Updater is a mechanism (to be implemented by you) which tests the different TopBDIIs and decides to remove or add DNS entries through DNS dynamic updates. The fault tolerance is implemented by dynamically removing the DNS “A” records of unavailable TopBDII(s). [http://linux.yyz.us/nsupdate/ nsupdate] introduced in bind V8 offers the possibility of changing DNS records dynamically: | * The DNS Updater is a mechanism (to be implemented by you) which tests the different TopBDIIs (siteBDII) and decides to remove or add DNS entries through DNS dynamic updates. The fault tolerance is implemented by dynamically removing the DNS “A” records of unavailable TopBDII(s) (siteBDIIs). [http://linux.yyz.us/nsupdate/ nsupdate] introduced in bind V8 offers the possibility of changing DNS records dynamically: | ||
# The nsupdate tool connects to a bind server on port 53 (TCP or UDP) and can update zone records | # The nsupdate tool connects to a bind server on port 53 (TCP or UDP) and can update zone records | ||
# Updates are authorized based on keys | # Updates are authorized based on keys | ||
| Line 111: | Line 111: | ||
* Status information about the BDII is available by querying the o=infosys root for the UpdateStats object. This entry contains a number of metrics relating to the latest update such as the time to update the database and the total number of entries. And example of such entry is shown below. | * Status information about the BDII is available by querying the o=infosys root for the UpdateStats object. This entry contains a number of metrics relating to the latest update such as the time to update the database and the total number of entries. And example of such entry is shown below. | ||
$ ldapsearch -x -h <TopBDII> -p 2170 -b "o=infosys" | $ ldapsearch -x -h <TopBDII/siteBDII> -p 2170 -b "o=infosys" | ||
(...) | (...) | ||
dn: Hostname=localhost,o=infosys | dn: Hostname=localhost,o=infosys | ||
| Line 131: | Line 131: | ||
* More extensive information can be obtained (modifyTimestamp,createTimestamp) adding the ''+'': | * More extensive information can be obtained (modifyTimestamp,createTimestamp) adding the ''+'': | ||
$ ldapsearch -x -h <TopBDII> -p 2170 -b "o=infosys" + | $ ldapsearch -x -h <TopBDII/siteBDII> -p 2170 -b "o=infosys" + | ||
(...) | (...) | ||
# localhost, infosys | # localhost, infosys | ||
| Line 191: | Line 191: | ||
</center> | </center> | ||
* Previous BDII metrics can be checked to take a decision regarding the reliability and availability of a TopBDII instance. | * Previous BDII metrics can be checked to take a decision regarding the reliability and availability of a TopBDII (siteBDII) instance. | ||
* More information is available in [https://twiki.cern.ch/twiki/bin/view/EGEE/BDII#Monitoring_the_BDII_Instance gLite-BDII_top Monitoring]. | * More information is available in [https://twiki.cern.ch/twiki/bin/view/EGEE/BDII#Monitoring_the_BDII_Instance gLite-BDII_top Monitoring]. | ||
| Line 250: | Line 250: | ||
! Date | ! Date | ||
! Comments | ! Comments | ||
|- | |||
| 1.1 | |||
| Paolo Veronesi | |||
| 2012-06-21 | |||
| This manual is equally applicable to site BDII, added some notes about it. | |||
|- | |- | ||
| 1.0 | | 1.0 | ||
Revision as of 08:58, 21 June 2012
| Main | EGI.eu operations services | Support | Documentation | Tools | Activities | Performance | Technology | Catch-all Services | Resource Allocation | Security |
| Documentation menu: | Home • | Manuals • | Procedures • | Training • | Other • | Contact ► | For: | VO managers • | Administrators |
(EMI.gLite) top-BDII and site-BDII High Availability
| Title | (EMI.gLite) top-BDII and site-BDII High Availability |
| Document link | https://wiki.egi.eu/wiki/MAN05 |
| Last review | v1.0, June 2011 |
| Policy Group Acronym | OMB |
| Policy Group Name | Operations Management Board |
| Contact Person | G. Borges, P. Veronesi |
| Document Status | APPROVED |
| Approved Date | 21 June 2011 |
| Procedure Statement | This manual provides information on how to deploy the BDII service in High Availability configuration. It is equally applicable to site and top BDII |
This document objective is to provide guidelines to improve the availability of the information system, addressing three main areas:
- Requirements to deploy a TopBDII (siteBDII) service
- High Availability from a client perspective
- Configuration of a High Availability TopBDII (siteBDII) service
Requirements to deploy a TopBDII (siteBDII) service
Hardware
- dual core CPU
- 10GB of hard disk space
- 2-3 GB RAM. If you decide to set BDII_RAM_DISK=yes in your YAIM configuration, it's advisable to have 4GB of RAM.
Co-hosting
- Due to the critical nature of the information system with respect to the operation of the grid, the TopBDII (siteBDII) should be installed as a stand-alone service to ensure that problems with other services do not affect the BDII. In no circumstances should the BDII be co-hosted with a service which has the potential to generate a high load.
Physical vs Virtual Machines
- There is no clear vision on this topic. Some managers complain that there are performance issues related to deploying a TopBDII (siteBDII) service under a virtual machine. Others argue that such performance issues are related to the configuration of the service itself. The only agreed feature is that the management and disaster recovery of any service deployed under a virtual machine is more flexible and easier. This could be an important point to take into account considering the critical importance of the TopBDII (siteBDII) service.
Best practices from a client perspective for top-BDII
- In gLite 3.2 and EMI you can set up redundancy of TopBDIIs for the clients (WNs and UIs) setting up a list of TopBDII instances to support the automatic failover in the GFAL clients. If the first Top level BDII fails to be contacted, the second will be used in its place, and so on. This mechanism is implemented defining the BDII_LIST YAIM variable according to the following syntax:
BDII_LIST=topbdii.domain.one:2170[,topbdii.domain.two:2170[...]].
- After running YAIM, the client enviroment should contain the following definition:
LCG_GFAL_INFOSYS=topbdii.domain.one:2170,topbdii.domain.two:2170
- The data management tools (lcg_utils) contact the information system for every operation (lcg-cr, lcg-cp, ...). So, if you have your client properly configured with redundancy for the information system, the lcg_utils tools will use that mechanism in a transparent way. Be aware that lcg-infosites doesn't work with multiple BDIIs. Only gfal, lcg_utils, lcg-info and glite-sd-query.
- Site administrators should configure their services with this failover mechanism where the first TopBDII of the list should be the default TopBDII provided by their NGI.
Best practices for a TopBDII (siteBDII) High Availability service
- The best practice proposal to provide a high availability TopBDII (siteBDII) service is based on two mechanisms working as main building blocks:
- DNS round robin load balacing
- A fault tolerance DNS Updater
We will provide a short introduction to some of these DNS mechanisms but for further information on specific implementations, please contact your DNS administrator.
DNS round robin load balacing
- Load balancing is a technique to distribute workload evenly across two or more resources. A load balancing method, which does not necessarily require a dedicated software or hardware node, is called round robin DNS.
- We can assume that all transactions (queries to top-bdii (siteBDII)) generate the same resource load. For an effective load balancing, all top-bdii (siteBDII) instances should have the same hardware configurations. In other case, a load balancing arbiter is needed.
- Simple round robin DNS load balancing is easy to deploy. Assuming that there is a primary DNS server (dns.top.domain) where the DNS load balancing will be implemented, one simply has to add multiple A records mapping the same hostname to multiple IP addresses under the core.top.domain DNS zone. It is equally applicable to site BDII.
# In dns.top.domain: Add multiple A records mapping the same hostname to multiple IP addresses Zone core.top.domain topbdii.core.top.domain IN A x.x.x.x topbdii.core.top.domain IN A y.y.y.y topbdii.core.top.domain IN A z.z.z.z
- The 3 records are always served as answer but the order of the records will rotate in each DNS query
- This does NOT provide fault tolerance against problems in the TopBDIIs (siteBDIIs) themselves
- if one TopBDII (siteBDII) fails its DNS “A” record will still be served
- one in each three DNS queries will provide the failed TopBDII (siteBDII) first answer
Fault tolerance DNS Updater
- The DNS Updater is a mechanism (to be implemented by you) which tests the different TopBDIIs (siteBDII) and decides to remove or add DNS entries through DNS dynamic updates. The fault tolerance is implemented by dynamically removing the DNS “A” records of unavailable TopBDII(s) (siteBDIIs). nsupdate introduced in bind V8 offers the possibility of changing DNS records dynamically:
- The nsupdate tool connects to a bind server on port 53 (TCP or UDP) and can update zone records
- Updates are authorized based on keys
- Updates can only be performed on the DNS primary server
- In the DNS bind implementation, the entire zone is rewritten by the DNS server upon “stop” to reflect the changes. Thefore, the zone should not be managed manually; and the changes are kept in a zone journal file until a “stop” happens.
Implementation
- There are several alternatives to implement the DNS Updater:
- NAGIOS based tests
- a demonized service
- scripts running as crons
What to test: BDII metrics
- Status information about the BDII is available by querying the o=infosys root for the UpdateStats object. This entry contains a number of metrics relating to the latest update such as the time to update the database and the total number of entries. And example of such entry is shown below.
$ ldapsearch -x -h <TopBDII/siteBDII> -p 2170 -b "o=infosys" (...) dn: Hostname=localhost,o=infosys objectClass: UpdateStats Hostname: lxbra2510.cern.ch FailedDeletes: 0 ModifiedEntries: 4950 DeletedEntries: 1318 UpdateTime: 150 FailedAdds: 603 FailedModifies: 0 TotalEntries: 52702 QueryTime: 8 NewEntries: 603 DBUpdateTime: 11 ReadTime: 0 PluginsTime: 4 ProvidersTime: 113
- More extensive information can be obtained (modifyTimestamp,createTimestamp) adding the +:
$ ldapsearch -x -h <TopBDII/siteBDII> -p 2170 -b "o=infosys" + (...) # localhost, infosys dn: Hostname=localhost,o=infosys structuralObjectClass: UpdateStats entryUUID: 09bf40e0-7b23-4992-af55-fd74f036a454 creatorsName: o=infosys createTimestamp: 20110612223435Z entryCSN: 20110615120723.216201Z#000000#000#000000 modifiersName: o=infosys modifyTimestamp: 20110615120723Z entryDN: Hostname=localhost,o=infosys subschemaSubentry: cn=Subschema hasSubordinates: FALSE
- The following table shows the meaning of the most relevant metrics:
| Metric | Desciption |
|---|---|
| ModifiedEntries | The number of objects to modify |
| DeletedEntries | The number of objects to delete |
| UpdateTime | To total update time in seconds |
| FailedAdds | The number of add statements which failed |
| FailedModifies | The number of modify statements which failed |
| TotalEntries | The total number of entries in the database |
| QueryTime | The time taken to query the database |
| NewEntries | The number of new objects |
| DBUpdateTime | The time taken to update the database in seconds |
| ReadTime | The time taken to read the LDIF sources in seconds |
| PluginsTime | The time taken to run the plugins in seconds |
| ProvidersTime | The time taken to run the information providers in seconds |
- Previous BDII metrics can be checked to take a decision regarding the reliability and availability of a TopBDII (siteBDII) instance.
- More information is available in gLite-BDII_top Monitoring.
DNS caching
- DNS records obtained in queries are cached by the DNS servers (usually during 24 hours). Therefore to propagate DNS changes fast enough it is important to have very short TTL lifetimes.
- DNS has not been built to have very short TTL values and these may increase highly the number of queries and as result increase the load of the DNS server
- The TTL lifetime to be used will have to be tested.
- If the top BDII are only used by sites in the region and if queries are only from the DNS servers of these few sites then the number of queries may be low enough to allow for a very small TTL
- This value should not be lower than 30s - 60s
Example 1: The IGI Nagios based mechanism
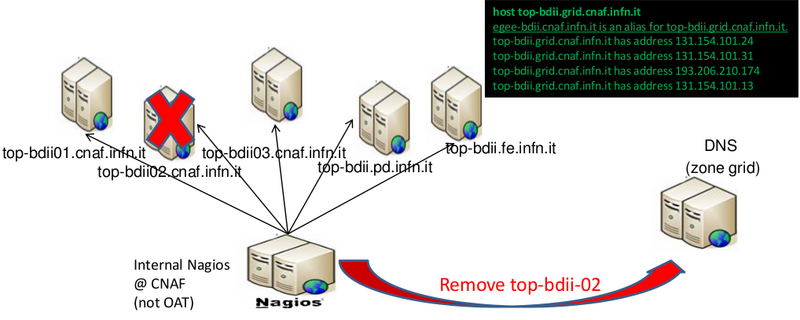
- In IGI, the DNS update of the number of instances participating in the DNS round robin mechanism depends on the results provided by a Nagios instance.
- When Nagios needs to check the status of a service it will execute a plugin and pass information about what needs to be checked. The plugin verifies the operational state of the service and reports the results back to the Nagios daemon.
- Nagios will process the results of the service check and take appropriate action as necessary (e.g. send notifications, run event handlers, etc).
- Each instance is checked every 5 minutes. If a failure occurs, Nagios runs the event handler to restart the BDII service AND remove the instance from the DNS round robin set using dnsupdate:
- an email is sent as notification;
- If 4 (out of 5) instances are failing, a SMS message is sent as notification;
- If a failed instance appears to be restored, nagios will re-add it to the DNS round robin mechanism.

- This approach has some single points of failures:
- The Nagios instance can fail
- The master DNS where the DNS entries are updated can fail
Example 2: The IBERGRID scripting based mechanism
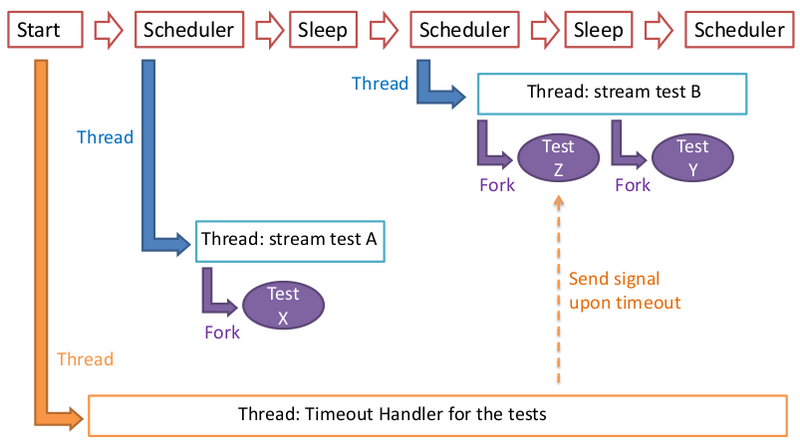
- In IBERGRID, an application (developed by LIP) verifies the health of each TopBDII. The application can connect to the DNS servers and remove the “A” records of TopBDIIs that become unavailable (non responsive to tests).
- The monitoring application (nsupdater) is a simple program that performs tests, and based on their result acts upon DNS entries
- Written in perl
- Can be run as daemon or at the command prompt
- The tests are programs that are forked
- Tests are added in a "module" fashion way
- Can be used to manage several DNS round robin scenarios
- Can manage multiple DNS servers

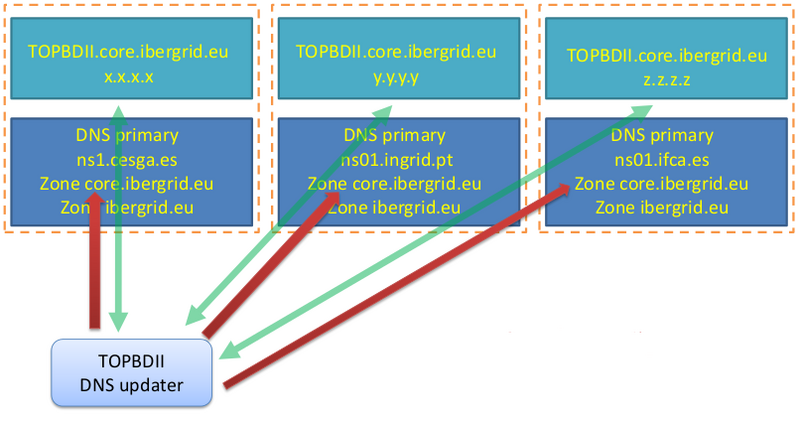
- To remove the DNS single point of failure as in previous example, one could configure all DNS servers serving the core.ibergrid.eu domain as primary
- Three primary servers would then exist for core.ibergrid.eu
- All three DNS servers could be dynamically updated independently
- The monitoring application should also have three instances, one running at each site
- The downside is that DNS information can become incoherent. It would be up to the monitoring application to manage the three DNS servers content and their cohe

Revision history
| Version | Authors | Date | Comments |
|---|---|---|---|
| 1.1 | Paolo Veronesi | 2012-06-21 | This manual is equally applicable to site BDII, added some notes about it. |
| 1.0 | Goncalo Borges, Jorge Gomes, Paolo Veronesi | 2011-06-15 | first draft |